Articles
July 28, 2022
Research Review: ‘Multi-Modal 3D Human Pose Estimation with 2D Weak Supervision in Autonomous Driving’

# Autonomous Vehicles
Pedestrians show up in surprising ways in autonomous driving systems. Researchers used 2D annotation to efficiently identify them in all of their visual forms.

Barrett Williams
As anyone working on autonomous vehicles will tell you, accurately detecting pedestrians with near perfect accuracy is absolutely essential. As Waymo riders and Tesla owners alike will also tell you, pedestrian detection appears to be reliably robust.
Autonomous vehicles also need to be able to interpret bodily gestures: A prone human who might be hurt or injured, a crouching human changing a tire, or someone running into the road chasing a pet all might be detected as pedestrians, but a truly safe autonomous vehicle might need a slightly different response in all of these scenarios.
This is the issue Waymo and Google Brain researchers attempted to address in the paper “Multi-Modal 3D Human Pose Estimation with 2D Weak Supervision in Autonomous Driving” and in a subsequent blog post about this work. Their conclusion: You don’t need expensive 3D labels to train a reliable pedestrian pose estimator for every 2D pedestrian ground-truth image in a dataset.
Framing the Problem
To make accurate distinctions among pedestrians, the deep learning models that run on autonomous vehicles need to be capable of Human keyPoint Estimation (HPE). TensorFlow’s MoveNet is an example of “fast and accurate pose detection,” which can overlay keypoints and their connecting lines over a webcam image (even while running in a web browser).
Over the past decade, much research has covered “hand tracking” and “skeleton tracking” in indoor environments, with potential use cases such as virtual reality (VR) and augmented reality (AR).
However, pose estimation becomes much more complex in the realm of autonomous vehicles, because pedestrian size in 2D RGB camera frames varies widely, as does the resolution of pedestrians in 3D point cloud data, based on distance. Prior approaches to this problem have focused on analyzing 2D camera frames on their own or 3D LiDAR frames on their own.
But the new research from Waymo now takes 2D pedestrian labels, projects them into 3D to provide “weak labeling” for 3D LiDAR data, and uses only human-generated cuboid labels to validate the performance of the model. This method eliminates the cost and overhead involved in creating 3D labels for the training dataset.
The paper’s authors explain that large data collection efforts for autonomous vehicle applications in 3D (involving cuboid labels, typically, are very expensive in terms of time and money. Furthermore, LiDAR-based point cloud data is often sparse or has much lower density at longer distances. Thus, a pedestrian two meters away looks very different as a point cloud than does a pedestrian 50 meters away. With little peer-reviewed research discussing outdoor LiDAR data—most prior research focused on indoor, shorter-range “scenes”—the authors demonstrate that fusing 2D and 3D data can yield more robust detection than either 2D or 3D data alone.
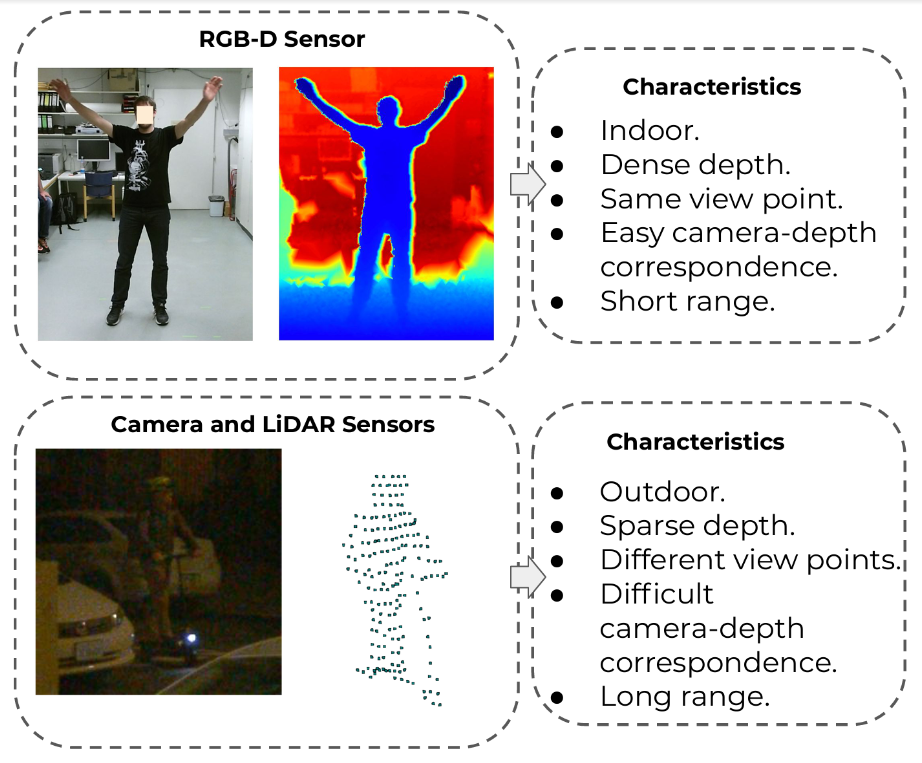
Figure 1. A comparison of indoor depth mapping characteristics (typically for augmented or virtual reality) and those of outdoor scenes (typically for autonomous vehicles) that incorporate both 2D and 3D sensors. Source: “Multi-Modal 3D Human Pose Estimation with 2D Weak Supervision in Autonomous Driving”
The goal of Human Pose Estimation is to project K points that represent a human pose. Point cloud P is the subset of the points that represent the pedestrian in the LiDAR point cloud. The authors landed on 13 keypoints representing the various symmetrical joints of the human body, plus the human nose. At the high level, the detector first feeds in a 2D RGB image from the input camera. The output of this model is then fed into a point-cloud network similar to PointNet that also consumes input LiDAR data.
The Model
The first model generates a heatmap, representing the likelihood of keypoint locations on the 2D image. The output of this model is very “peaky”—it has very high and low values but few intermediate ones. Thus, a Gaussian filter smooths out this distribution slightly so as not to unduly bias the final output of the full model. These heatmaps are then projected onto the point cloud and sampled based on probability. This set of points with likelihood scores are then used as features, concatenated with the LiDAR point cloud. Colors from the 2D RGB camera are assigned to the points in the point cloud, “colorizing” them.
The end result from the 2D-plus-3D model, as distinct from a model that learns only on point clouds, is a 6% mean-average-precision (mAP) improvement. But the authors don’t stop there. They add a second “arm” to their model; this “arm” assumes that the 2D skeleton predictions should present clusters of 3D LiDAR points around the prediction of those 2D keypoints.
With a temperature-controlled (parameterized) softmax function, the output of this arm yields “pseudo-labels,” or “weak supervision” of the keypoints as a subset of the LiDAR point cloud. Using these pseudo-labels, the authors observed a 22% relative improvement on the Waymo Open Dataset compared to using 2D images alone.
In the set of four images in Figure 2, you can see that image (a) is relatively limited in its fidelity, with the 13 keypoints clustered around the center of the child’s torso. Images (b) through (d) distribute the keypoints better across the pedestrian child’s body, and the authors attribute (d) as having the most accurate distribution (particularly on the knees, wrists, and feet). Also, the authors trained keypoint detection models with the Inception and ResNet models as bases, for quantitative comparison.

Figure 2. Side-by-side comparisons of human keypoints detected on LiDAR only (a), a small-input Inception model (b), a larger-input Inception model (c), and a more traditional large-input ResNet model (d). Source: “Multi-Modal 3D Human Pose Estimation with 2D Weak Supervision in Autonomous Driving”
This is somewhat surprising because Inception (2016) is a more modern and recent network than ResNet-50 (2014). But perhaps resolution is a key factor here, since the input to ResNet-50 is much higher resolution, at 256 by 256 pixels, compared to two lower resolutions for the Inception model tested, as you can see in Figure 2.
Perhaps one of the more unique or distinguishing features of this paper is the choice of training losses. Training losses represent a metric that the learning process uses to determine whether the model is improving or regressing with every additional “epoch” or readjustment of the model’s weights. Thus, the loss is to be minimized to maximize the performance of the model.
The authors determine that Huber loss is most useful for the pseudo-3D labels, while image segmentation performs best when cross-entropy is the guiding metric. The camera network is trained on mean squared error (MSE, which is very standard), based on the ground-truth 2D heatmap. Once training is completed, the network is frozen except for the final layer, which is continually retrained based on the hybrid output of 2D and 3D input training data.
The authors also discovered that pseudo-labels for occluded key points (for example, if an elbow or a wrist was not visible to the camera due to an obstacle such as a parked vehicle) only decreased the performance of the model (see Figure 3).
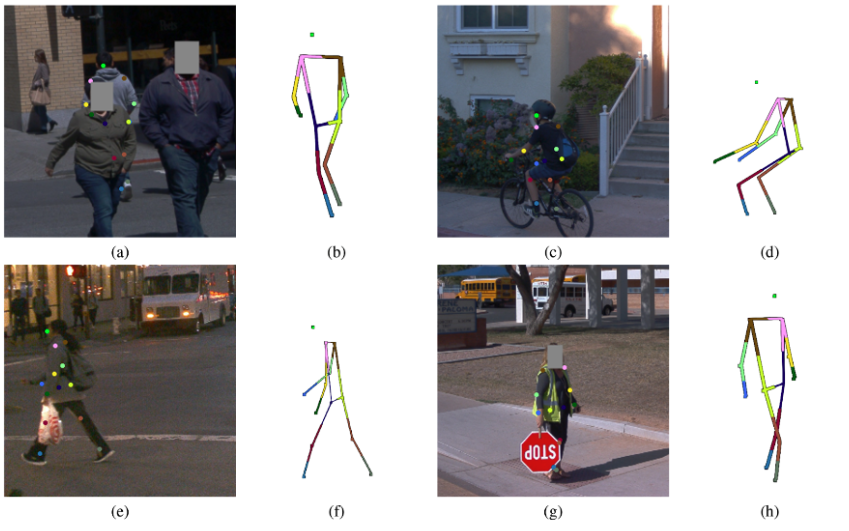
Figure 3. Comparisons of hybrid (2D plus 3D) model output, as applied to different human poses. Source: “Multi-Modal 3D Human Pose Estimation with 2D Weak Supervision in Autonomous Driving”
Takeaways: Perceiving Pedestrians
With merely a subset, and projection of keypoints from 2D onto the point cloud data, the hybrid model outperforms either LiDAR or camera data alone. 2D labels are cheap and plentiful compared to 3D cuboids. 3D and 2D data can be leveraged to achieve higher pedestrian pose detection accuracy by transferring 2D labels into the 3D domain to retrain the model for higher accuracy.
The examples in Figure 3 don’t represent perfect keypoint classifications—compare a and b with particular attention to the pedestrian’s left foot, shaded in gray—but they do show that the model performs robustly based on both 2D data and 3D pseudo-labels. Human-in-the-loop review of these examples might further increase quality.
More broadly, this research defines a new state of the art for pedestrian pose recognition. This means that, increasingly, autonomous vehicles will be able to interpret gestures from crossing guards, law enforcement officials, and emergency services personnel, decreasing the likelihood of injury or fatal collisions with pedestrians who cross paths with autonomous vehicles.
Moreover, this method doesn’t require pedestrians; it could involve any deformable object for which 2D labels are cheap and 3D labels are expensive or nontrivial.
Learn More
- Read the original research paper: “Multi-Modal 3D Human Pose Estimation with 2D Weak Supervision in Autonomous Driving”
Popular
Video
ML at Waymo: Building a Scalable Autonomous Driving Stack with Drago Anguelov
By Dragomir Anguelov
Dive in
Related
Video
Blueprint to Agentic AI: Identify, Build, Deploy
By Sahil Bhaiwala • Apr 30th, 2025 • Views 1.5K
Video
Making AI Work: How to Build and Scale Long-Running Enterprise Agents
Nov 21st, 2025 • Views 554
Video
Making AI Work: How to Build and Scale Long-Running Enterprise Agents
Nov 21st, 2025 • Views 554
Video
Blueprint to Agentic AI: Identify, Build, Deploy
By Sahil Bhaiwala • Apr 30th, 2025 • Views 1.5K